
문제 정의
원툴의 높은 가용성 확보와 사용자 경험 향상을 위해 여러 성능 개선을 시도하고 있다. 우리 팀은 현재 가지고 있는 기술을 통해 문제를 해결해보고, 불가능할 경우 새로운 기술 도입을 검토하는 것을 지향한다. 그 중 가장 문제가 될 수 있다고 판단한 부분이 SLOW QUERY이다. 결국 대량의 데이터가 쌓일 경우, 예기치 못한 문제가 충분히 발생할 수 밖에 없기 때문이다.
이를 위해 100만 건의 더미 데이터를 삽입한 뒤 쿼리 속도를 측정한 결과, Long Query가 발생하는 것을 발견했다. 이 경우, 한 커넥션이 오랫동안 붙잡고 있어 전체적인 성능 저하 및 병목이 발생한다. 따라서, 인덱스를 생성하여 쿼리를 개선해보고자 한다.

더미 데이터는 총 10가지 1차 카테고리, 5가지의 2차 카테고리가 랜덤하게 분포되어 있다. 또한, 도면명과 작가명은 랜덤한 단어들의 조합으로 이루어져 있다.
분석 및 진단
특정 카테고리의 도면을 조회하는 API의 응답 속도가 서비스의 기준치보다 느렸다. 데이터가 증가함에 따라, 특정 조건으로 데이터를 필터링하는 데이터베이스 쿼리에서 Full Table Scan이 발생하여 성능 저하를 유발하는 것으로 예상했다.
먼저 사용된 데이터베이스 서버의 사양은 다음과 같다.
- DB 버전: MySQL 8.0.41
- vCPU: 2
- 메모리: 8GB
서브 쿼리와 JOIN 비교
BlueprintRepository의 여러 쿼리 중, 다중 조건(categoryId, secondCategory, inspectionStatus, is_deleted)을 사용하는 findAllBySecondCategory 메소드가 가장 복잡하고 성능 저하의 핵심 원인일 것이라 판단했다.
기존 쿼리는 서브 쿼리를 바탕으로 작동을 하고 있었다. 이 쿼리를 JOIN으로 치환할 경우 얼마만큼의 성능 개선이 이루어지는지 확인하고자 아래 쿼리를 직접 실행하였다.
-- 서브 쿼리
SELECT *
FROM blueprint b
WHERE b.second_category = '3D'
AND b.category_id = (SELECT f.id FROM first_category f WHERE f.name = 'civil')
AND b.inspection_status = 'PASSED'
AND b.is_deleted = 'false'
ORDER BY b.id DESC
LIMIT 20 OFFSET 100;
-- JOIN
SELECT *
FROM blueprint b INNER JOIN first_category f
ON b.category_id = f.id
WHERE b.second_category = '3D'
AND f.name = 'building'
AND b.inspection_status = 'PASSED'
AND b.is_deleted = 'false'
ORDER BY b.id DESC
LIMIT 20 OFFSET 100;


약간이나마 근소하지만, 평균적으로 JOIN보다 서브쿼리가 약 200ms 정도 더 빠른 것을 발견했다. 왜 이런 결과가 나온 것인지 EXPLAIN ANALYZE를 통해 실행 계획을 분석해보았다.
[서브 쿼리]
-> Table scan on b (cost=100337 rows=954586)
(actual time=0.0865..1066 rows=1e+6 loops=1)
-> Select #2 (subquery in condition; run only once)
-> Filter: (f.`name` = 'civil') (cost=0.85 rows=1)
(actual time=0.0115..0.0174 rows=1 loops=1)
-> Table scan on f (cost=0.85 rows=6)
(actual time=0.0103..0.016 rows=6 loops=1)
[JOIN]
-> Inner hash join (b.category_id = f.id) (...) (...)
-> Filter: ((b.inspection_status = 'PASSED') and (b.second_category = '3D')) (cost=96423 rows=4773) (actual time=0.0756..1264 rows=99834 loops=1)
-> Table scan on b (cost=96423 rows=954586)
(actual time=0.0709..1080 rows=1e+6 loops=1)
-> Hash
-> Filter: (f.`name` = 'building') (cost=0.85 rows=1)
(actual time=0.059..0.0667 rows=1 loops=1)
-> Table scan on f (cost=0.85 rows=6)
(actual time=0.0556..0.0623 rows=6 loops=1)
서브쿼리가 더 빠른 이유는 카테고리에 의한 필터링이 초반에 이루어지기 때문이다. 서브쿼리는 blueprint 테이블을 스캔할 때, category_id = 4 조건이 즉시 적용된다. 따라서, 메모리에 올려서 정렬해야 할 대상이 처음부터 10,112개로 줄어든 상태로 시작한다.
이와 반대로 JOIN 방식의 경우, blueprint 테이블을 스캔할 때, 아직 category_id가 무엇인지 모른다. 그래서 inspection_status와 second_category 조건만으로 1차 필터링을 합니다. 이때 남은 데이터가 99,834개다. 이 많은 데이터가 Inner hash join 단계로 넘어간다. 해시 조인 연산자가 10만 번의 비교를 수행한 뒤에야 데이터가 10,112개로 줄어든다.
비효율적인 쿼리 개선
쿼리를 자세히보면 가장 문제가 되는 부분은 첫번째 카테고리의 ID를 가지고 와야하는 비효율적인 부분이 있다. 즉, blueprint와 first_category에 대한 Table Scan을 각각 수행을 해야 하는 것이다. 그러나 도면 테이블의 칼럼을 자세히 보면 이미 첫번째 카테고리 ID를 가지고 있는 것을 확인할 수 있다.
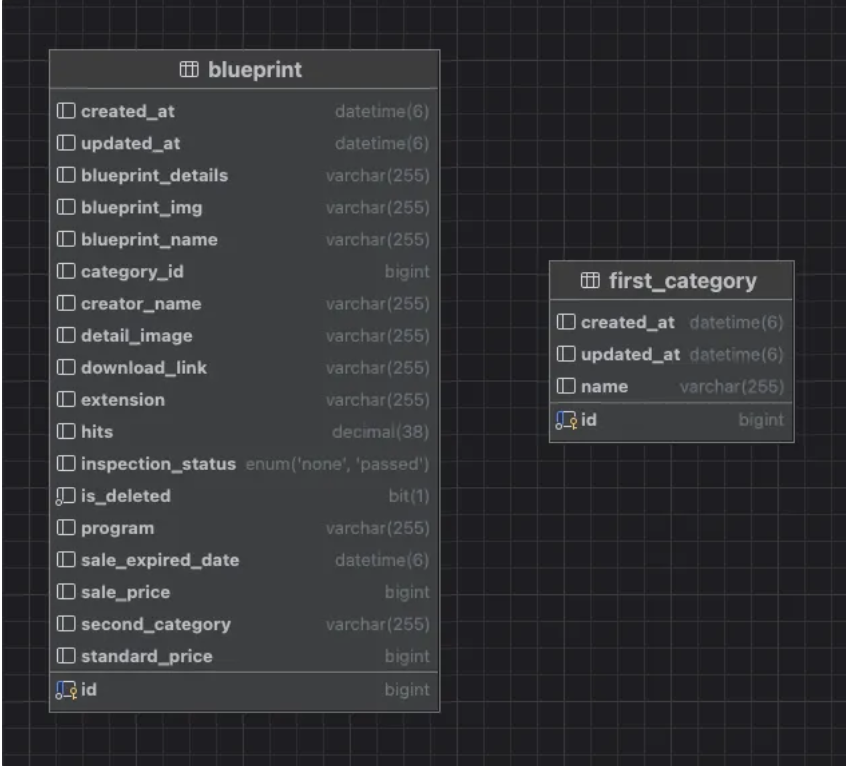
따라서 첫번째 카테고리 ID를 찾기 위해 first_category 테이블을 스캔할 이유가 없는 것이다. 따라서 도면 테이블만 이용하여 테이블을 이용할 수 있도록 단일 쿼리로 개선했다.
[단일 쿼리]
SELECT * FROM blueprint b
WHERE b.second_category = '3D'
AND b.category_id = 4
AND b.inspection_status = 'PASSED'
AND b.is_deleted = 'false'
ORDER BY b.id DESC
LIMIT 20 OFFSET 100;
그 결과, 1.8s에서 493ms까지 성능 개선을 이루어낼 수 있다. 여기서 더 나아가보고자 한다. 현재 검색 기능은 크게 카테고리 검색과 키워드 검색으로 나눌 수 있다. 전문 검색의 한계를 바탕으로 외부 검색 엔진 도입을 기획하고 있다. 그러나 카테고리 검색의 경우, 키워드 기반 검색보다 훨씬 많이 사용될 것으로 예측되고, 우리 서비스의 가장 핵심 기능 중 하나라고 생각된다. 따라서, 쿼리 구조 개선을 넘어 인덱스 적용을 통해 빠른 검색 속도를 바탕으로 더욱 빠른 기능 제공이 가능할 것으로 예상된다.
API 성능 측정해보기
쿼리 시간 측정보다 실제 유저 입장에서의 성능 측정을 위해 Postman를 이용하여 ‘2차 카테고리 검색’ 기능의 API 처리 시간을 측정해보았다.
2차 카테고리의 경우, 총 4개의 AND 절로 이루어진 매우 복잡한 쿼리이기 때문에 2.3초라는 매우 긴 시간이 소요된다. 더욱 효율적인 인덱싱을 위해 쿼리를 분석해보고자 한다.
쿼리 특성 파악하기
현재 카테고리 쿼리는 WHERE에서 category_id와 second_category, inspection_status를 기준으로 도면을 조회한다. 또한, 페이지네이션을 적용하기 때문에 LIMIT과 OFFSET을 이용하여 쿼리가 실행된다.
SELECT id, blueprint_name, category_id, standard_price, blueprint_img, extension, program, hits, sale_price, sale_expired_date, creator_name, secondary_category
FROM blueprint
WHERE category_id = 4
AND second_category = '공공'
AND inspection_status = 'PASSED';
AND is_deleted = 0
ORDER BY created_at DESC
LIMIT 20 OFFSET 100;
여기서 주목한 점은 여러 개의 컬럼이 AND로 연결되어 있어, 실제 레코드를 모두 찾아 모든 WHERE 절에 적합한 데이터를 가져오기 위해 Random I/O가 발생한다.
당연하게도 랜덤 I/O는 순차 I/O보다 비용이 꽤 크다. MySQL의 옵티마이저는 실제 데이터 레코드 수가 전체의 20~25%를 넘으면, 테이블의 인덱스를 타지 않고, 데이터를 직접 읽어 Table Full Scan을 이용한다. 따라서 페이지네이션 로직 적용함으로써 읽어야 할 데이터가 전체의 20~25%가 넘지 않는다.
따라서, 인덱스를 적용하여 이런 랜덤 I/O가 발생하지 않고, Index Scan을 하도록 유도하고자 한다. 그렇다면 인덱스를 고려하기 위한 체크리스트를 살펴보자.
인덱스 도입 체크리스트
인덱스는 매우 최소한의 컴럼에만 적용해야 한다. MySQL의 인덱스는 B+ Tree를 사용하는데, B+ Tree는 노드가 균형잡히도록 구현된 자료구조이다. 만약 데이터 변동이 심할 경우, 트리 균형 잡기 위해 재배치 작업이 이루어지게 된다. 이때 데이터베이스는 인덱스 무결성을 위해 쓰기 작업시 속도가 저하된다. 따라서 전체 성능에 영향을 줄 수 있다.
- 카디널리티가 높은가?
카디널리티란 '중복되지 않는 고유한 값의 개수'를 의미한다. 만약 카디널리티가 낮은 경우, 중복된 값들로 인해 인덱스를 타는 효과가 미미하여 거의 Table Scan을 하는 것과 같아지거나 더 느려질 수도 있다.
현재, category_id와 second_category, inspection_status , is_deleted 총 4가지로WHERE 절이 이루어져 있다. 이 중 inspection_status와 is_deleted는 각각 2가지의 값만을 가질 수 있기 때문에 카디널리티가 낮다. 그러나 나머지 카테고리에 대해선 각각 10개, 제한 없음 이기 때문에 충분히 사용 가능하다고 판단했다.
- 선택도가 20~25% 이하인가?
일반적으로 데이터의 20~25% 이하를 걸러낼 수 있을 때 인덱스가 효율적이다. 그 이상을 조회한다면 옵티마이저는 풀 스캔을 선택할 가능성이 높다. 아까 이야기한 바와 같이 페이지네이션을 사용하기 때문에, 조회할 도면은 한 번에 20개 밖에 되지 않는다. 따라서, 이 체크리스트에도 부합된다.
- 자주 변경되는 데이터들로만 이루어져있는가?
현재 도면의 경우, 우리 팀이 보유한 상품만 판매 및 거래를 진행하고 있다. 따라서, 조회를 제외한 변경이 거의 발생하지 않는 환경이다.
WHERE 절의 모든 컬럼으로 복합 인덱스를 구현해야 할까?
모든 컬럼을 넣을 경우, 당연히 랜덤 I/O를 줄일 수 있기 때문에 빠를 것이라고 생각된다. 그러나 아까 말했다시피 is_deleted와 inspection_status는 카디널리티가 낮기 때문에, 이를 어떻게 처리하는게 좋을지 실험해보고자 한다. 즉, 카디널리티가 미치는 영향을 파악하기 위해 여러 경우를 직접 측정해보자.
먼저 아래 인덱스를 생성하여 API를 측정해보자. 총 6가지의 경우를 바탕으로 인덱스를 사용해보았다.
| 인덱스 (순서 중요) | 결과 (ms) |
|---|---|
| inspection_status, is_deleted, category_id, second_category, created_at | 922 |
| category_id, second_category, inspection_status, is_deleted, created_at | 1386 |
| category_id, second_category | 534 |
| econd_category, category_id | 740 |
| second_category | 713 |
| category_id | 1344 |
아래 쿼리처럼 1차 카테고리와 2차 카테고리만으로 이루어진 복합 인덱스에서 눈에 띄는 성능 개선이 발생했다.
CREATE INDEX idx_blueprint_composite
ON blueprint (category_id, second_category);
당연하지만, 카디널리티가 낮은 칼럼까지 포함할 경우 테이블 스캔을 하는 거나 마찬가지이다. 그런데 거기에 더해 많은 칼럼수로 인해 인덱스 크기 자체가 커져 인덱스를 순회하는데에도 많은 시간이 소요되는 것을 알 수 있다. 또한 인덱스를 잘 타는지도 실행 계획을 통해 확인해보았다.
-> Limit/Offset: 20/100 row(s) (cost=6588 rows=20)
(actual time=1.15..1.22 rows=20 loops=1)
-> Filter: (b.inspection_status = 'PASSED') (cost=6588 rows=18824)
(actual time=0.344..1.21 rows=120 loops=1)
-> Index lookup on b using idx_blueprint_composite
(category_id=4, second_category='3D',
is_deleted=0, inspection_status='PASSED')
(cost=6588 rows=18824) (actual time=0.309..1.15 rows=120 loops=1)
불필요한 칼럼 삭제
여기서 더 최적화를 하기 위해 현재 꼭 필요한 칼럼만 패치 해오도록 수정하려고 한다. InnoDB의 경우, 자주 접근하는 데이터를 버퍼 풀에 캐시하여 디스크 접근을 줄인다. SELECT *를 사용할 경우, 실제로 필요한 데이터 대신 불필요한 컬럼들로 인해 캐시가 빠르게 차게 된다. 이 때문에 캐시 히트율이 떨어지고 성능이 저하가 발생한

현재 조회된 도면에선 blueprint_img, creator_name, blueprint_name, standard_price, program 총 4가지의 칼러만 필요하다. SELECT *을 사용할 경우 16개의 칼럼을 모두 패치해오기 때문에 4배나 많은 데이터를 패치해오게 된다. 여기에 추가적으로 도면 상세페이지 접근을 위한 ID를 추가로 넘겨 총 5개의 칼럼만 가져오도록 개선해보자.
SELECT id, blueprint_img, creator_name, blueprint_name, standard_price, program
FROM blueprint
WHERE
category_id = 4
AND secondCategory = '공공'
AND inspectionStatus = 'PASSED'
AND isDeleted = 'false'
ORDER BY id DESC
LIMIT 20 OFFSET 100;
결과
이번 개선 작업을 통해 2차 카테고리 검색 기능을 2.3초에서 0.2초로 약 10,000배의 성능 향상을 이루어냈다. 이 과정에서 서브쿼리와 JOIN의 성능 차이 와 카디널리티에 따른 인덱스 효율 , SELECT * 의 성능 저하를 직접 경험하고 해결할 수 있었다. 또한, 인덱스를 적용하기 전에 체크리스트를 기반으로 과연 정당한 사용 근거가 있는지도 파악하는 과정을 가졌다. 여기에서 더 높은 성능 개선을 하기 위해선 Redis 나 Caffeine을 이용한 캐싱 전략이 도입되어야 한다. 따라서, 이번에는 인덱싱으로 어느정도의 성능 개선이 가능한지 파악하는 것을 직접 느끼고 배울 수 있었다.
'DB' 카테고리의 다른 글
| [DB] MySQL과 pgSQL의 트랜잭션 격리 수준과 이상 현상 (0) | 2025.11.27 |
|---|